
2021 yılında, bu sahteciliği otaya çıkaran raporu kaleme alan Uri Simonsohn, Joe Simmons ve Leif Nelson’un da içinde bulunduğu anonim araştırmacılardan oluşan bir ekip, Gino tarafından ortaklaşa yazılan bir dizi çalışmayı incelemişlerdi çünkü bunların hileli veriler içerdiğine dair endişeler bulunuyordu.Bu yazıda kendi bloglarında yer alan 3 farklı yazının birleştirilmiş ve özetlenmiş halini bulabilirsiniz. Orijinal yazıları okumak isteyenler için linkler yazının en altında bulunmaktadır.
Yakın zamanda (2020’de) yayınlanan makaleler de dahil olmak üzere on yılı aşkın bir süreyi kapsayan makalelerde sahtekarlık yapıldığına dair kanıtlar belirlenmiştir. 2021 Sonbaharında ekip endişelerini Harvard Business School (HBS) ile paylaşmıştır. Özellikle, sahtekarlığa dair en güçlü kanıtların toplandığı dört çalışma hakkında bir rapor yazmışlardır. Ayrıca ekip Gino’nun yazdığı daha birçok makalenin sahte veriler içerdiğine inanmaktadır. Belki de düzinelerce.
Bu raporun paylaşımı sonucu şunlar gerçekleşmiştir:
(1) Harvard ana sayfasında görebileceğiniz gibi, Gino “idari izne” ayrılmıştır ve HBS’deki başkanlık pozisyonunun adı artık listelenmemektedir.
(2) Harvard’ın, Qualtrics anket yazılımı kullanılarak toplanan orijinal veriler de dahil olmak üzere, bizden çok daha fazla bilgiye erişimi olduğu anlaşılmaktadır. Eğer sahtekarlık Qualtrics’te gerçek verilerin toplanması ve daha sonra indirilen veri dosyalarının değiştirilmesi suretiyle gerçekleştirilmişse, ki bu makalelerden üçü için durum muhtemelen böyledir, o zaman orijinal Qualtrics dosyaları sahtekarlığa dair sağlam kanıtlar sağlayacaktır. (Tersine, eğer endişeler yanlış yönlendirilmişse, o zaman bu dosyalar yanlış yönlendirildiklerine dair sağlam kanıtlar sağlayacaktır).
(3) Harvard’ın raporda yer alan dört makaleden üçünün geri çekilmesini talep ettiğini (Harvard dışındaki bilgili kaynaklardan) öğrenilmiştir. Yazıda tartışılan dördüncü bir makale zaten geri çekilmişti, ancak Harvard’ın geri çekme bildiriminin bu (ek) sahtekarlıktan bahsedecek şekilde değiştirilmesini talep ettiğini anlıyoruz.
(4) Raporda detaylandırılan sahtekarlık kanıtları, Harvard müfettişlerinin bu dört makale hakkında ortaya çıkarabildikleri kanıtların neredeyse sadece bir alt kümesini temsil etmektedir. Örneğin, bazı HBS öğretim üyelerinden Harvard’ın iç raporunun ~1.200 sayfa uzunluğunda olduğu bilgisi alınmıştır ki, bu da yazarlar tarafından HBS’ye gönderilen rapordan 1.182 sayfa daha uzun.
(5) Bilindiği kadarıyla, Gino’nun ortak yazarlarından hiçbiri söz konusu çalışmalar için veri toplamamış ya da toplanmasına yardımcı olmamıştır.
Bölüm 1: Clusterfake
Shu, Mazar, Gino, Ariely ve Bazerman (2012), Çalışma 1
“Signing at the beginning makes ethics salient…..” Ulusal Bilimler Akademisi Bildiriler Kitabı
İki yaz önce, sahtekârlıkla ilgili ünlü bir makalede bildirilen bir çalışma hakkında bir yazı yayınlamıştır. Bu çalışma bir otomobil sigorta şirketinde (The Hartford) yürütülen bir saha deneyiydi. Dan Ariely tarafından yönetilmiştir ve uydurulmuş veriler içermektedir. Bu verileri kimin uydurduğu kesin olarak bilinmemektedir, ancak Ariely’nin ortak yazarlarından hiçbirinin – Shu, Gino, Mazar veya Bazerman – bunu yapmadığından konusunda raporu yazan ekip emindir . Makale o zamandan beri geri çekilmiştir.
Bu otomobil sigortası saha deneyi, makaledeki Çalışma 3’tür. Aynı zamanda makaledeki Çalışma 1’in verileriyle de oynandığı ortaya çıkmıştır… ama farklı bir kişi tarafından.
İki farklı kişi, sahtekârlıkla ilgili bir makalede iki farklı çalışma için bağımsız olarak veri sahteciliği yapmıştır.
Makalede yer alan üç çalışmanın, insanların dürüstlük taahhütnamesini bir formun en altında değil de en üstünde imzaladıklarında dürüst davranmama ihtimallerinin daha düşük olduğunu gösterdiği iddia edilmekteydi. Çalışma 1, 2010 yılında Kuzey Carolina Üniversitesi’nde (UNC) yürütülmüştür. 2010’da Harvard’a katılmadan önce UNC’de profesör olan Gino, Çalışma 1’in veri toplama ve analizinde yer alan tek yazardı.
Çalışma Açıklaması
Katılımcılara (N = 101) 20 matematik bulmacası içeren bir çalışma sayfası verilmiş ve 5 dakika içinde doğru çözdükleri (bildirdikleri) her bulmaca için 1 dolar teklif edilmiştir.
5 dakika geçtikten sonra, katılımcılardan kaç bulmacayı doğru çözdüklerini saymaları ve ardından çalışma sayfalarını atmaları istenmiştir. Amaç, katılımcıları, deneycinin gerçek performanslarını gözlemleyemeyeceğini düşünmeleri konusunda yanıltmaktı, oysa aslında gözlemleyebiliyordu, çünkü her çalışma sayfasının benzersiz bir tanımlayıcısı vardı. Böylece katılımcılar yakalanma korkusu olmadan hile yapabilir (ve daha fazla para kazanabilir), araştırmacılar ise her bir katılımcının ne kadar hile yaptığını gözlemleyebilirdi.
Katılımcılar daha sonra ne kadar para kazandıklarını ve ayrıca laboratuvara gelmek için ne kadar zaman ve para harcadıklarını bildiren bir formu doldurdular. Deneyciler bu masraflar için katılımcılara kısmen tazminat ödemiştir.Özetle, katılımcılar kaç bulmacayı doğru çözdükleri ve laboratuvara gelmek için yaptıkları masraflar hakkında yalan söyleme fırsatına ve teşviğine sahiptiler. Çalışma, söz konusu formların katılımcıların üstünü mü yoksa altını mı imzalamalarını (ya da hiç imzalamamalarını) gerektirdiğini manipüle etmiştir.

Sonuçlar
Makalede çok büyük etkiler rapor edilmiştir. Üstte ve altta imza atmak, matematik bulmaca performanslarını fazla bildirenlerin oranını %79’dan %37’ye düşürmüş (p = .0013) ve ortalama fazla bildirme miktarını 3,94 bulmacadan 0,77 bulmacaya indirmiştir (p < .00001). Benzer şekilde, iddia edilen işe gidip gelme masraflarının ortalama tutarını 9,62 dolardan 5,27 dolara düşürerek neredeyse yarıya indirmiştir (p = .0014).
Veri Anomalisi: Sıra Dışı Gözlemler
Verileri, orijinal yazarların da dahil olduğu bir araştırmacı ekibi tarafından yürütülen bir replikasyon sonucunda 2020’den beri yayınlandığı Açık Bilim Çerçevesinden elde edilmiştir.
Yayınlanan veriler iki sütuna göre sıralanmış gibi görünmektedir; ilk olarak katılımcıların koşul atamasını gösteren “Cond” adlı bir sütuna göre (0 = kontrol; 1 = üstte işaret; 2 = altta işaret) ve ardından deneyci tarafından atanan Katılımcı Kimlik numarasını gösteren “P#” adlı bir sütuna göre. Örneğin, aşağıdaki ekran görüntüsü, üstte işaret ve altta işaret koşullarından bazı gözlemlerle birlikte bu elektronik tablonun bir bölümünü göstermektedir. Her koşulda verilerin Katılımcı Kimliğine (soldaki ilk sütun) göre neredeyse mükemmel bir şekilde sıralandığı görülebilmektedir. Burada önemli olan, sıralamanın yalnızca neredeyse mükemmel olmasıdır.
Yinelenen ya da sıra dışı olan 8 gözlem ekip tarafından vurgulanmıştır:

Katılımcı kimliği 49, aynı demografik bilgilerle veri kümesinde iki kez görünmektedir. Buna ek olarak, bitişik satırlarda, üçü koşul 1’de (Üstteki İşaret), üçü de koşul 2’de (Alttaki İşaret) olmak üzere, sıra dışı kimliklere sahip 6 katılımcı bulunmaktadır. Bu durum göründüğünden çok daha sorunludur.
Raporu yazan ekibin ifadesine göre bu sıralamayı elde etmek için verileri sıralamanın bir yolu yoktur. Bu da bu veri satırlarının ya elle yerlerinin değiştirildiği ya da P#’lerin elle değiştirildiği anlamına gelmektedir. Bunun birincisi olduğunu görülmüştür. Eğer bu veri tahrifatı istenen sonucu elde etmek için motive bir şekilde yapıldıysa, o zaman bu şüpheli gözlemlerin üstteki işaret ile alttaki işaret manipülasyonu için özellikle güçlü bir etki göstermesi beklenir.
Ve öyle de olmuştur.
Şüpheli Satırlar Büyük Bir Etki Gösteriyor
Aşağıdaki şekil, ilgilenilen iki koşuldaki tüm gözlemleri göstermektedir. Yukarıda bahsedilen 8 şüpheli gözlem, öngörülen yönde büyük bir etki göstermektedir. Hepsi de kendi koşulları içinde en uç gözlemler arasındadır ve hepsi de öngörülen yöndedir.

Bölüm 2: Sınıf Yılım Harvard
Gino, Kouchaki ve Galinsky (2015), Çalışma 4
“The Moral Virtue of Authenticity: How Inauthenticity Produces Feelings of Immorality and Impurity”, Psychological Science
Bu makalede yazarlar, özgün olmama deneyiminin insanların kendilerini daha ahlaksız ve iffetsiz hissetmelerine yol açtığını öne süren beş çalışma sunmuşlardır. Burada Harvard Üniversitesi’nde yürütülen Çalışma 4’e odaklanılmıştır.
Harvard öğrencileri (N = 491) çevrimiçi bir anket doldurmuştur. İlk olarak Harvard kampüsündeki bir sorun hakkında görüş bildirmeleri ve bazı demografik bilgiler vermeleri istenmiştir. Daha sonra bu konu hakkında kendi taraflarını savunan ya da kendi taraflarına karşı çıkan bir makale yazmaları istenmiştir .
Kompozisyonu yazdıktan sonra katılımcılar beş temizlik ürününü ne kadar cazip bulduklarını derecelendirmişlerdir (1 = Tamamen istenmeyen; 7 = Tamamen arzu edilen). Yazarlar, kendi düşünceleri aksine yazmanın katılımcıların kendilerini kirli hissetmelerine neden olacağını ve bunun da temizlik ürünlerine olan isteklerini artıracağını öngörmüşlerdir.
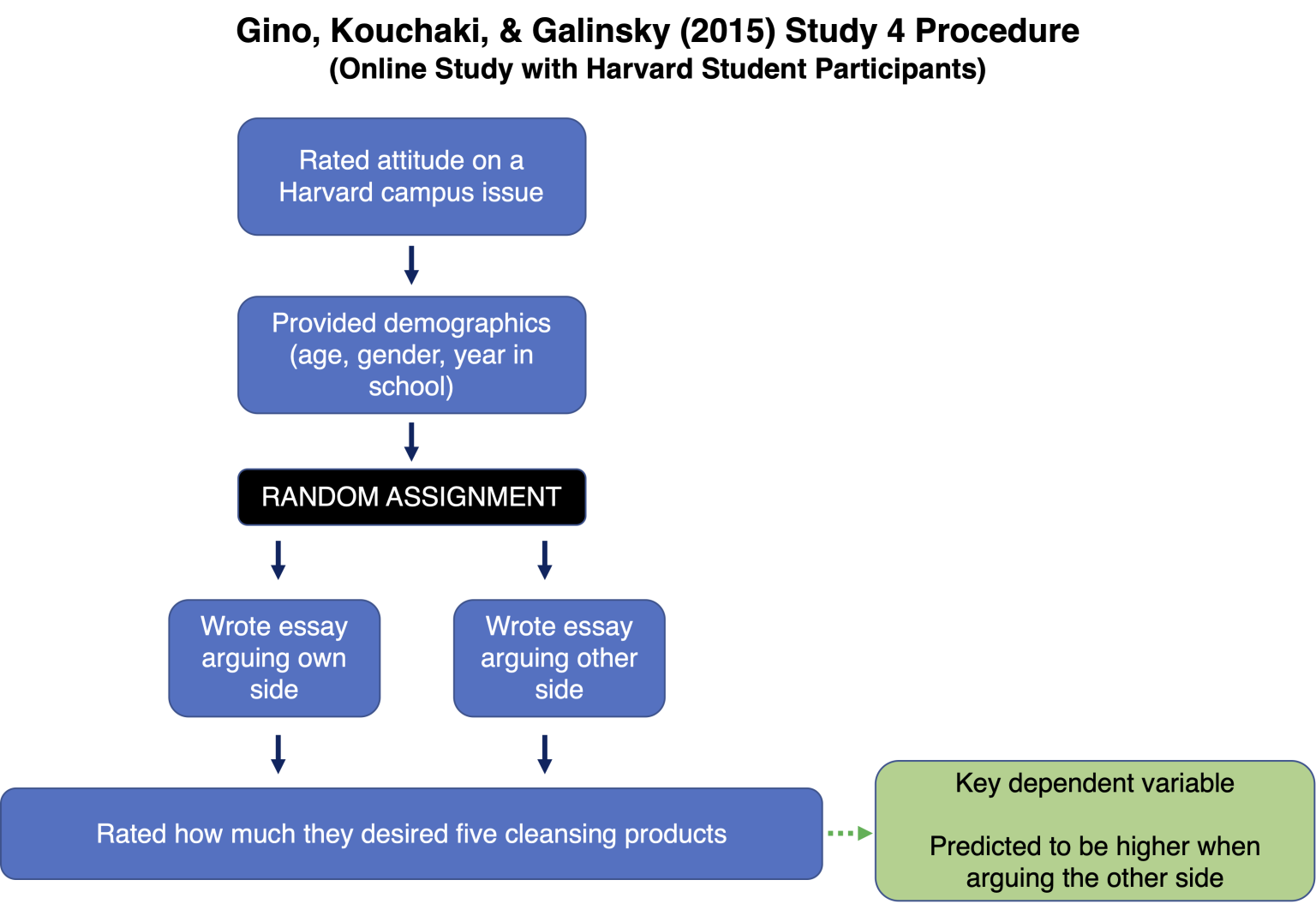
Sonuçlar
Yazarların hipotezleriyle tutarlı olarak, katılımcılar kendi taraflarına karşı (M = 4.26, SD = 1.48) ve kendi tarafları lehine (M = 3.72, SD = 1.33) tartışırken temizlik ürünlerini daha fazla arzulamışlardır, t(488) = 3.93, p < .0001.
Anormallik: Garip Demografik Yanıtlar
Yukarıda belirtildiği gibi, bu çalışmadaki öğrencilerden demografik bilgilerini bildirmeleri istenmiştir. Burada, tam olarak ne sorulduğunu ve nasıl sorulduğunu gösteren, yayınlanan orijinal materyallerin bir ekran görüntüsü yer almaktadır:

Verileri Gino’nun (ya da onun kimlik bilgilerini kullanan birinin) 2015 yılında yayınladığı OSF’den alınmıştır. Bu veri setindeki anormallik, bazı öğrencilerin Soru #6: “Okuldaki Yıl “ı nasıl yanıtladıklarıyla ilgilidir.
Aşağıdaki ekran görüntüsü veri setinin bir bölümünü göstermektedir. “YearSchool” sütununda, öğrencilerin bu “Okuldaki Yıl” sorusuna birkaç farklı şekilde yaklaştığını görebilirsiniz. Örneğin, üçüncü sınıftaki bir öğrenci “junior” veya “2016” veya “class of 2016” veya “3” (üçüncü sınıfta olduğunu belirtmek için) yazmış olabilir. Tüm bu yanıtlar makuldür.
Daha az makul bir yanıt olan “Harvard” ise soruya yanlış bir yanıttır. Birçok öğrencinin bağımsız olarak bu son derece kendine özgü hatayı yaptığını hayal etmek zordur. Bununla birlikte, veri dosyası 20 öğrencinin bunu yaptığını göstermektedir. Dahası, bu öğrencilerin yanıtları, yayınlanan veri kümesinde birbirlerinden 35 satır (450 ila 484) içinde yer almaktadır:

Tek başına bu, güçlü bir uyarı işaretidir. Bu kadar çok öğrencinin bu soruya böylesine garip bir yanıt vermesinin hiçbir nedeni yoktur. Bu durum, birilerinin verilerle bu kadar çok “Sınıf yılım Harvard” yanıtı verecek şekilde oynamış olabileceğini düşündürmektedir.
Eğer bu tuhaf gözlemlerle gerçekten oynanmışsa, o zaman “Harvard” cevabını veren öğrencilerin yazarların hipotezini doğrulama ihtimalinin özellikle yüksek olduğunu görmemiz gerekir. Aşağıdaki grafik, her gözlem için temel bağımlı değişkeni – katılımcıların beş temizlik ürününü ne kadar istediklerine dair ortalama derecelendirmelerini – göstermektedir. Her “normal” gözlem mavi bir nokta olarak gösterilirken, 20 “Harvard” gözlemi kırmızı X’ler olarak gösterilmiştir:

Tartışılan-diğer-taraf koşullarında her “Harvard” gözleminin mümkün olan en yüksek ortalama değere (yani 7.0) sahip olduğunu görebilirsiniz. Tersine, tartışılan-kendi tarafı koşulunda, biri hariç her “Harvard” gözlemi düşük bir değerle ilişkilendirilmiştir.
Sadece bu 20 gözlem için iki koşul arasındaki fark oldukça anlamlıdır (p < .000001). Dahası, ‘Harvard’ gözlemleri için etki, Harvard olmayan gözlemler için olandan önemli ölçüde daha büyüktür (p < .000001).
Bu durum, ‘Harvard’ gözlemlerinin istenen etkiyi yaratmak için değiştirildiğini kuvvetle düşündürmektedir. Ve eğer bu gözlemler değiştirildiyse, o zaman diğer gözlemlerin de değiştirildiğinden şüphelenmek mantıklıdır.
Aslında, bu seride ele alınan dört çalışmada da veri tahrifatına dair kanıtlar bulunmuş olsa da, bu çalışmalarda meydana gelen tüm tahrifatı tespit ettiğine (en azından) ekip inanmamaktadır. Ekip, orijinal (tahrif edilmemiş) veri dosyalarına – Harvard’ın erişimi olduğuna inandıkları dosyalara – erişim olmadan, yalnızca veri tahrifatçısının hata yaptığı, burada yeniden sıralamayı unuttuğu, orada bir kopyala-yapıştır hatası yaptığı durumları tespit edebiliceklerini düşünmektedir. Bir veri tahrifatçısının bir veritabanında bir şeyi değiştirirken hata yapmasının, o veritabanındaki tüm şeyleri değiştirirken de aynı hatayı yapmasını beklemek için (hiçbir) neden yoktur.
Bölüm 3: Hileciler Düzeni Bozdu
Gino & Wiltermuth (2014), Çalışma 4
“Evil Genius? How Dishonesty Can Lead to Greater Creativity?’ Psychological Science
Bu makalede yazarlar, sahtekârlığın yaratıcılığa yol açabileceğini öne süren beş çalışma sunmaktadır. Burada, mTurk katılımcıları kullanılarak çevrimiçi olarak yürütülen Deney 4’e odaklanılmaktadır. Bu veri setini birkaç yıl önce doğrudan Profesör Gino’dan almışlardır.
Katılımcılara (N = 178) ilk olarak, onlara hile yapma teşviki ve fırsatı veren sanal bir yazı tura atma görevi sunulmuştur. Kurallara uymayı ölçen bir ölçeği tamamladıktan sonra , katılımcılar iki yaratıcılık görevini tamamlamışlardır. Burada sadece katılımcılardan “1 dakika içinde bir gazete için mümkün olduğunca çok sayıda yaratıcı kullanım alanı (işlev) üretmelerini” isteyen “kullanımlar” görevinin sonuçlarına odaklanılmaktadır . Araştırmacılar bu görevi yaratıcılığı değerlendirmenin bir yolu olarak kullanmışlardır.
Sonuçlar
Yazarların hipoteziyle tutarlı olarak, yazı tura atma görevinde hile yapan katılımcılar, hile yapmayan katılımcılara (M = 6.5, SD = 2.3) kıyasla gazete için daha fazla kullanım alanı (M = 8.3, SD = 2.8) bulmuşlardır, p < .0001.
Anomali: Sıra Dışı Gözlemler
Bölüm 1’de olduğu gibi, bu veri setinde de hile yapıldığına dair en önemli işaret verilerin nasıl sıralandığından gelmektedir. Veri kümesi iki sütuna göre neredeyse mükemmel bir şekilde sıralanmıştır; ilk olarak katılımcıların yazı tura görevinde hile yapıp yapmadıklarını gösteren “hile yaptı” sütunu (0 = hile yapmadı; 1 = hile yaptı) ve ardından katılımcının bir gazete için kaç kullanım ürettiğini gösteren “Yanıt sayısı” sütunu.
Yazı 1’de olduğu gibi, sıralamanın neredeyse mükemmel olması göründüğünden daha sorunludur. Aşağıdaki ekran görüntüsü veri kümesindeki ilk 40 gözlemi göstermektedir Veriler ilk olarak “hile yapılan” sütununa göre sıralandığından, bu gözlemlerin tümü hile yapmayanları temsil etmektedir (“hile yapılan” sütunundaki puanlar 0’dır) ve “Yanıt sayısı” sütununa göre mükemmel bir şekilde sıralanmıştır. Gerçekten de, veri setindeki hile yapmayan 135 gözlemin tümü “Yanıt sayısı” sütununa göre mükemmel bir şekilde sıralanmıştır.

Bir sonraki ekran görüntüsü ise 43 hile yapanın bu değişkene göre de sıralandığını, ancak olması gereken sırada olmayan 13 gözlem olduğunu göstermektedir:

Bu gözlemlerin sıra dışı olduğuna inanılmaktadır çünkü istenen etkiyi yaratmak için değerleri manuel olarak değiştirilmiştir (sıralandıktan sonra).
Burada dikkat edilmesi gereken üç husus vardır:
1. Veri kümesini, verilerin kaydedildiği sırayı üretecek şekilde sıralamak mümkün görünmemektedir. Veriler ya başlangıçta bu şekilde girilmiştir (ki bu pek mümkün değildir, çünkü veriler varsayılan olarak zamana göre sıralama yapan bir Qualtrics dosyasından gelmektedir) ya da manuel olarak değiştirilmiştir.
2. Satırların bağımlı değişken olan “Numberofreponses “a göre sıralandığını hatırlayın. Sıra dışı olan değerler değiştirilmişse, neye göre değiştirildiklerini bulmak kolaydır. Örneğin, 141 numaralı satırda “13” vardır. Üstündeki satırda “4” vardır ve ondan sonraki ilk sıradaki değer “5 “tir. Dolayısıyla, veriler değiştirildiyse, bu “13 “ün eskiden “4” ya da “5” olduğunu varsayabiliriz.
Aşağıda iki yeni sütun görebilirsiniz – “ImputedLow” ve “ImputedHigh” – bu sütunlar isnat edilecek iki olası değere sahiptir. Bazı durumlarda tam olarak hangi sayının isnat edileceğini biliyoruz, bazı durumlarda ise +-1 içinde bilinmektedir.

Aşağıdaki şekil, sıra içi ve sıra dışı gözlemleri ve isnatları grafiksel olarak göstermektedir:

3. Hile ve yaratıcılık arasındaki anlamlı ilişki, paylaşılan veri kümesindekiler yerine bu atanan değerleri analiz ettiğinizde kaybolur. P-değeri p < .0001’den p = .292’ye (“ImputedLow”) veya p = .180’e (“ImputedHigh”) düşmektedir. Dolayısıyla, eğer bu değerler elle değiştirilmeden önce elektronik tablodaki konumlarına eşit olsaydı, hile yapanlar ile yapmayanlar arasında önemli bir fark olmazdı.
Ortalamaların Ötesinde
Kemerlerinizi bağlayın, bu son bölüm biraz daha teknik. Ama raporu yazan ekip tarafından buna değeceği düşünülmektedir.
Hile yapanlar ile yapmayanlar arasında bir gazete için kullanım üretme becerileri açısından gerçekten hiçbir fark olmadığını düşünün. Veri tahrifatının olmadığı bir durumda, sadece ortalama gazete kullanım sayısının aynı olmasını beklemekle kalmazdık. Bu değişkenin tüm dağılımının da aynı olmasını bekleriz. Örneğin, yüzde 20’lik dilimde hangi değerin yer aldığı hem hile yapanlar hem de yapmayanlar için aynı olmalıdır. Bu aynı zamanda 50. yüzdelik dilim, 80. yüzdelik dilim ve 90. yüzdelik dilim için de geçerlidir.
Bu 13 değeri eski haline getirildiğinde, sadece benzer ortalamalar değil, aynı zamanda çok benzer dağılımlar da gözlemlenmiştir. Bunu, hem bu değerleri dorğu olduğu düşünülen değerlere dönüştürmeden önce (sol panel) hem de dönüştürdükten sonra (sağ panel) kümülatif dağılım fonksiyonlarını (CDF’ler) gösteren aşağıdaki şekilde görebilirsiniz.

Şimdi, sağ paneldeki bu dağılımlar ne kadar benzer? Nicel bir yanıt vermek için, tüm dağılımları parametrik olmayan bir şekilde karşılaştırmak için kullanılan Kolmogorov-Smirnov (KS) testi uygulanmıştır. Elde edilen sonuç p = .456, yani iki dağılımın aynı olduğu hipotezini reddetmemizi gerektirmiyor. Tamam, ama bu bulgu ne kadar etkileyici? Bunu, olması gerektiği düşünülen değere döndürülen 13 gözlemin aslında veri analistinin tahrif ettiği 13 gözlem olduğunun ve sadece onların tahrifatını bu yolla geri alındığının kanıtı olarak alınmaktadır. Ama belki de bu doğru değildir. Belki de hangi 13 gözlemi değiştirdiğiniz önemli değildir. Peki ya diğer 13 (hileci) gözlemi de değiştirilseydi ve bunlar değiştirdirilmiş olan miktarlarda değiştirilseydi? Yine bu kadar benzer dağılımlar (yani KS testinde bu kadar yüksek bir p-değeri) elde edilir miydi?
Kısacası: Hayır.
Bazı ( ihtiyatlı) simülasyonlar gerçekleştirilmiştir. İsnatlardan 13 değer değişikliği alınmış, ancak bunları değiştirildiğini belirlenen 13 gözleme değil, rastgele seçilen 13 hile yapanlara ait gözleme uygulanmıştır. Hile yapanlar için bağımlı değişkenin ortalamasını her zaman aynı miktarda düşürüldüğüne dikkat edin: Her bir simülasyonda her zaman 6.95’e (8.3’ten) düşmüştür. Burada değiştirien tek şey hangi hile yapan deneklerin değerlerinin değiştirildiğiydi. Bu bir milyon kez simüle edilmiştir. Her seferinde hile yapanlarla yapmayanların benzerliği KS testi ile değerlendirilmiş ve p-değerini takip edilmiştir. Sonuçlar aşağıdadır. Bu 13 gözlemi seçmek ve dağılımların gruplar arasında sadece şans eseri bu kadar benzer olmasını sağlamak için son derece, gülünç derecede şanslı olunması gerekirdi.

Başka bir deyişle, bu kadar benzer iki dağılım elde etmek için bu miktarda değiştirebileceğiniz (neredeyse) farklı bir 13 değer kümesi yoktur. Bu sonuçları, hangi hücrelere müdahale edildiğini ve değerlerinin ne kadar değiştirildiğini doğru bir şekilde belirlendiği (güçlü bir şekilde) şeklinde yorumlanmaktadır.
Orijinal yazılar:
Makaleler/Blog Yazıları:
Bölüm 1 – https://datacolada.org/109
Bölüm 2 – https://datacolada.org/110
Bölüm 3 – https://datacolada.org/111

{kind=link}